Group 37 CS4824 Final Project
Khang Lieu, Anthony Huynh
Summary of Original Paper Results
Original Paper: Don't Decay the Learning Rate, Increase the Batch SizeThe researchers in the paper concludes that increasing the batch size during training achieves the same learning curve on both training and test sets as decaying the learning rate, which is the more common approach. They tested and found that this procedure of increasing the batch size rather than decaying the learning rate is successful for stochastic gradient descent(SGD), SGD with momentum, Nesterov momentum, and Adam.
Reproducing the Original Paper's Results
We decided to reproduce the results on a Convolutional Neural Network implemented using the TensorFlow framework in Python. We used the tutorial on Datacamp.com on how to build CNNs on TensorFlow located here. This tutorial seemed best suited for our project, as it provided an easy way to vary the batch size and learning rate in steps. They utilize the Adam optimizer, one of the most popular optimization algorithm and one of the optimizers that supports the claim in Don't Decay the Learning Rate, Increase the batch size.
Decaying the Learning Rate
The following line was added to define the learning rate as a
dynamically changing value.
learning_rate = tf.train.exponential_decay(starter_learning_rate,
global_step,decay_steps, decay_rate, staircase=True)
starter_learning_rate is defined as either 0.001 or 0.005,
as labeled in the graphs in the measurements section. Starting with too
big of a learning rate could keep the accuracy low, while starting too
small of a learning rate may decay it too fast to see meaningful
results. The default value for the learning rate in TensorFlow for the
Adam optimizer is 0.001. global_step keeps track of
how many batches have been processed by the program.
decay_steps defines how many steps before the learning rate
is decayed.
1 epoch = # of images / batch size = steps per
epoch
60000 / 128 = 468.75 steps per epoch.
468.75 steps per epoch * 60 epochs = 28125 steps per 60 epochs.decay_rate
defines the rate at which the learning rate is decayed. The paper states
that they decayed the learning rate by a factor of 5, so the decay rate
is 0.2.
The batch size was kept constant at 128. The learning rate is set to decay by a factor of 5 every 60 epochs.
Increasing the Batch Size
In the for loop where the training happens, if statements are added to multiply the batch sizes by 5 and store it within itself every 60 training intervals or epochs. The learning rate was set constant at 0.001.
Measurements and Analysis
Measurements
In our attempt to reproduce the results of the experiment we adjusted the batch size and learning rate of two convolutional neural networks optimized using the Adam algorithm. One network periodically increased the batch size by a factor of 5 and the other network periodically decreased the learning rate by a factor of 5. The networks were trained over 200 epochs with the batch size increased and the learning rate decreased after 60, 120, and 180 epochs had passed. The datasets used were the MNIST handwritten digit dataset and the Fashion-MNIST dataset.
Analysis
To verify that increasing the batch size had a comparable effect to decreasing the learning rate we graphed the training and testing accuracies of the neural networks. By visually comparing the results of the increased batch size and decreased learning rate accuracies, we can determine if they have an equivalent effect.
Learning Rate
The neural networks with decreasing learning rates was trained and tested with a base learning rate of 0.001 and 0.005. The networks were trained over 200 epochs, with the learning rate decreasing by a factor of 5 after 60,120, and 180 epochs.
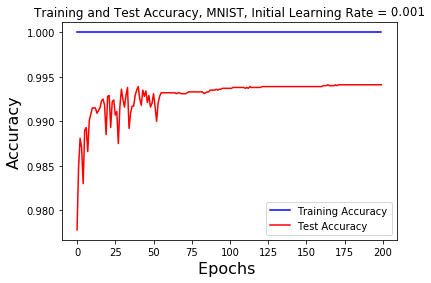
For the graph of the training and test accuracy on the MNIST dataset with an initial learning rate of 0.001, we find that at around 40 epochs the test accuracy maxes out at around the 40 epochs mark, so it isn't possible to see how decaying the learning rate affects the test accuracy.
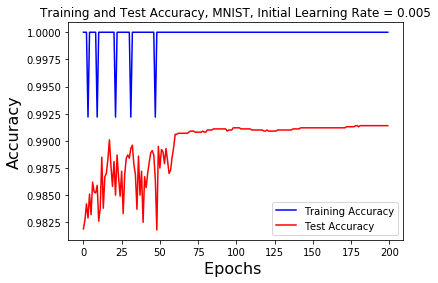
For the graph of the training and test accuracy on the MNIST dataset with an initial learning rate of 0.005, it is clear that when the learning rate is reduced by a factor of 5 at the 60 epochs mark, the test accuracy increases to a new high. Around the 120 epochs mark when the learning rate is reduced again we can see that the test accuracy slightly increases from it's current value. At the 180 epochs mark we can see a little bounce on the graph showing that the learning rate was reduced, but the test accuracy remains the same and plateaus.
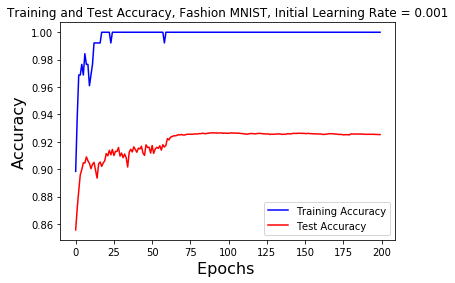
For the graph of the training and test accuracy on the Fashion MNIST dataset with an initial learning rate of 0.001, the first learning rate decay at the 60 epochs mark raises the test accuracy to a new high. The second and third learning rate decays at the 120 and 180 epochs mark does not show any changes in the test accuracy. It seems to have maxed out a little over 92%.
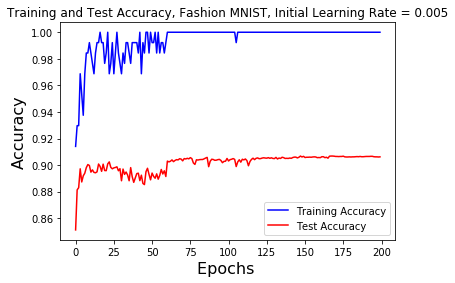
For the graph of the training and test accuracy on the Fashion MNIST dataset with an initial learning rate of 0.001, the first learning rate decay at the 60 epochs mark raises the test accuracy to barely a new high. At the 120 epochs mark the test accuracy jumps from a minima back to around where it was before the learning rate was decayed and plateaus. Decaying the learning rate around the 180 epochs mark does not seem to affect the test accuracy.
Batch Size
The batch size neural network was trained and tested with a base batch size of 128 and 256 for both the MNIST and Fashion-MNIST datasets. As previously stated after 60, 120, and 180 epochs had been run the batch size was increased by a factor of 5.
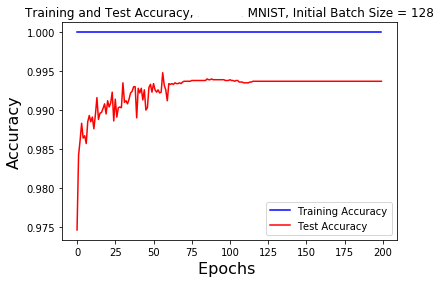
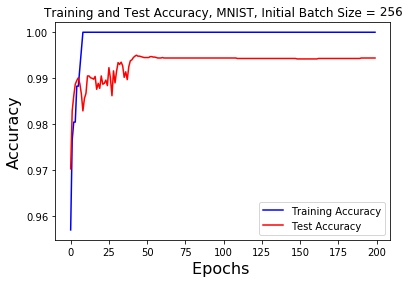
From the graphs showing the accuracy of the MNIST dataset there are clear jumps in the testing accuracy around the 60 epoch point. For the 128 base batch size the training accuracy was constantly 100% and the test accuracy stayed constant at about 99.4%. For the 256 base batch size the training accuracy jumps to 100% after 10 epochs and the testing accuracy plateaus before the 50 epoch point, remaining constant between 99% and 100%. Increasing the batch size at the 120 and 180 epoch points had no effect on the accuracy.
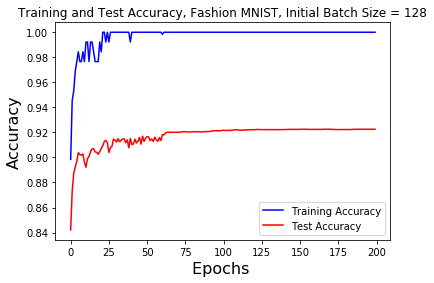
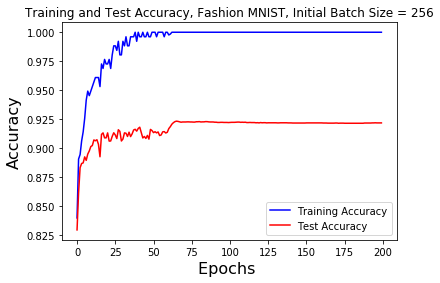
When using the Fashion-MNIST dataset the acccuracy was similar to the MNIST. The training accuracy jumps from 98% to 100% after the 25 epoch point. The testing accuracy of the 128 base batch size was slightly erratic prior to the 60 epoch point, after which it smoothed out to 92%. With a 256 base batch size the training accuracy quickly increases to 100% by the 60 epoch point and stays there. The testing accuracy had a more pronouced jump in accuracy at the 60 epoch point before staying constant at 92.5%. Neither batch size increases at the 120 and 180 epoch point impacted the accuracy.
Conclusion
In conclusion, when comparing the shape of the accuracies of the decreasing the learning rate and increasing the batch size graphs, they have similar shape and values. Comparing the graph of the decaying learning rate on the Fashion MNIST dataset with an initial learning rate of 0.001 and the graph of the increasing the batch size on the Fashion MNIST dataset with an initial batch size of 128 they have the same shape, but the test accuracy plateaus higher at a higher value. From the Datacamp.com tutorial that we started with, they achieved around 92% test accuracy before the graph became stagnant. Comparing the graph of the decaying learning rate on the MNIST dataset with an initial learning rate of 0.001 and the graph of the increasing the batch size on the MNIST dataset with an initial batch size of 128 they have the same shape and the test accuracy plateaus at almost the same value. In this article, the writer applies CNN on the MNIST dataset and achieves an accuracy of 99.55%, and says that the state of the art result has a test accuracy of 99.79%. Our graphs for the MNIST datasets becomes stagnant a little under 99.5%. The graphs we generated have the same shape as the graph in figure 4a in Don't Decay the Learning Rate, Increase the batch size. We ran the training with different initial values for both the learning rate and batch size to see if it would make a difference in the graph shapes, but they remained the same. We can't conclude that increasing the batch size has exactly the same effect on test accurary as decaying the learning rate, although they do produce very similar graphs, but we can deduce that decreasing the learning rate and increasing the batch size does have a positive effect on the training and testing accuracies of convolutional neural networks using the Adam optimizer.
References
- [1] Smith, Samuel L., et al. "Don't decay the learning rate, increase the batch size." arXiv preprint arXiv:1711.00489 (2017).
- [2] Radiuk, Pavlo M. "Impact of training set batch size on the performance of convolutional neural networks for diverse datasets." Information Technology and Management Science 20.1 (2017): 20-24.
- [3] Devarakonda, Aditya, Maxim Naumov, and Michael Garland. "AdaBatch: adaptive batch sizes for training deep neural networks." arXiv preprint arXiv:1712.02029 (2017).
- [4] Sharma, Aditya. “Convolutional Neural Networks in Python with TensorFlow.” DataCamp Community, 9 Mar. 2018, www.datacamp.com/community/tutorials/cnn-tensorflow-python.
- [5] Katariya, Yash. “Applying Convolutional Neural Network on the MNIST Dataset.” Applying Convolutional Neural Network on the MNIST Dataset – Yash Katariya – CS Grad @ NCSU, yashk2810.github.io/Applying-Convolutional-Neural-Network-on-the-MNIST-dataset/.